GPT series
PloutosGPT
2024-02-08 https://arxiv.org/abs/2403.00782
基于BERT
FinBERT-19
2019-08-27 https://arxiv.org/abs/1908.10063
FinBERT-20
2020-07-09 https://arxiv.org/abs/2006.08097
FinBERT-21
2020
https://www.ijcai.org/proceedings/2020/0622.pdf
Mengzi-BERT-base-fin
2021-10-14
https://arxiv.org/abs/2110.06696
https://huggingface.co/Langboat/mengzi-bert-base-fin
澜舟科技 https://www.langboat.com/
基于Text-to-text transfer transformer (T5)
BBT-Fin:乾元大模型 BBT (Big Bang Transformer)-FinT5
2023-02-26
 超对称(北京)科技有限公司 https://bbt.ssymmetry.com/
超对称(北京)科技有限公司 https://bbt.ssymmetry.com/
基于ELECTRA
FLANG
2022-10-31
官网 https://salt-nlp.github.io/FLANG/
基于BLOOM
BloombergGPT
2023-12-21 https://arxiv.org/abs/2303.17564
XuanYuan 2.0
2023-05-19 https://arxiv.org/abs/2305.12002 https://huggingface.co/xyz-nlp/XuanYuan2.0 基于 BLOOM-176B Scao 等人( 2022 年) 的模型,具有数千亿个参数,旨在满足中国金融领域的独特需求并促进复杂的对话式 AI 系统的发展。
基于Llama
PIXIU/FinMA
2023-06-08 https://arxiv.org/abs/2306.054430 https://huggingface.co/TheFinAI/finma-7b-full
Cornucopia-LLaMA-Fin-Chinese
聚宝盆(Cornucopia): 基于中文金融知识的LLaMA微调模型 2023-05-07
Instruct-FinGPT
2023-06-22 https://huggingface.co/papers/2306.12659
InvestLM
2023-09-15 https://arxiv.org/abs/2309.13064
Fin Llama 33B Merged
2023-11-29 https://huggingface.co/bavest/fin-llama-33b-merged 官网 https://www.bavest.co/de
基于Llama2
FinLlama
2024-03-18 https://arxiv.org/abs/2403.12285
FinGPT
2023-06-09
https://arxiv.org/abs/2306.06031
V Alpha Tross
2024-09(约)
https://huggingface.co/gradientai/v-alpha-tross
The v-alpha-tross model is based on meta-llama/Llama-2-70b-hf, with additional, finance specific, pre-training, fine-tuning and instruction tuning.
v-alpha-tross 模型基于 meta-llama/Llama-2-70b-hf ,并附加了针对财务的预训练、微调和指令调整。
官网 https://www.gradient.ai/
GreedLlama
2024-04-03 https://arxiv.org/abs/2404.02934
基于Llama3
Llama-3-SEC
2024-06(约) Llama-3-SEC:一种最先进的领域特定大型语言模型,它将彻底改变我们分析和理解 SEC(美国证券交易委员会)数据的方式。Llama-3-SEC 建立在强大的 Meta-Llama-3-70B-Instruct 模型之上,正在大量 SEC 文件和相关财务信息上进行训练。
Finance Llama3 8B
2024-06-21 https://huggingface.co/instruction-pretrain/finance-Llama3-8B 我们通过提出_指令预训练来探索有监督的多任务预训练 ,该框架可以使用指令-响应对可扩展地扩充海量原始语料库来预训练语言模型。指令-响应对由基于开源模型构建的高效指令合成器生成。指令预训练_在从头开始的一般预训练和领域自适应持续预训练中均优于 Vanilla 预训练。 在从头开始的预训练中, 指令预训练不仅可以改进预训练的基础模型,还可以从进一步的指令调整中受益更多。 在持续预训练中, 指令预训练使 Llama3-8B 能够与 Llama3-70B 相媲美甚至超越 Llama3-70B。
LLaMA 3 8B GRPO Finance Math TR
2025-03-23 https://huggingface.co/Metin/LLaMA-3-8B-GRPO-Finance-Math-TR Metin/LLaMA-3-8B-GRPO-Finance-Math-TR 是 ytu-ce-cosmos/Turkish-Llama-8b-DPO-v0.1 的 RL 训练版本。它使用 GRPO 方法针对金融数学问题进行训练。
WiroAI Finance Llama 8B
2025-03-24|LoRA https://huggingface.co/WiroAI/WiroAI-Finance-Llama-8B
WiroAI Finance Qwen 1.5B
https://huggingface.co/WiroAI/WiroAI-Finance-Qwen-1.5B
WiroAI Finance Gemma 9B
https://huggingface.co/WiroAI/WiroAI-Finance-Gemma-9B
基于Qwen
Tongyi-Finance-14B
2023-11-24 https://modelscope.cn/models/TongyiFinance/Tongyi-Finance-14B
Fin-R1
2025-03-20 https://github.com/SUFE-AIFLM-Lab/Fin-R1 https://arxiv.org/abs/2503.16252
上海财经大学联合财跃星辰开源首个金融领域R1类推理大模型Fin-R1
Fin-R1 是一款针对金融领域复杂推理的大型语言模型,由上海财经大学统计与数据科学学院张立文教授与其领衔的金融大语言模型课题组(SUFE-AIFLM-Lab)联合财跃星辰研发并开源发布。该模型以 Qwen2.5-7B-Instruct 为基座,通过高质量的可验证金融问题微调训练,最终表现在多个金融领域基准测试上的表现达到参评模型的SOTA水平。
我们基于 DeepSeek-R1 构建了数据蒸馏框架,并严格按照官方参数设定进行数据处理,采用两阶段数据筛选方法提升金融领域数据质量,生成了SFT数据集和RL数据集。在训练过程中,我们利用Qwen2.5-7B-Instruct,通过监督微调(SFT)和强化学习(RL)训练金融推理大模型 Fin-R1,以提升金融推理任务的准确性和泛化能力。
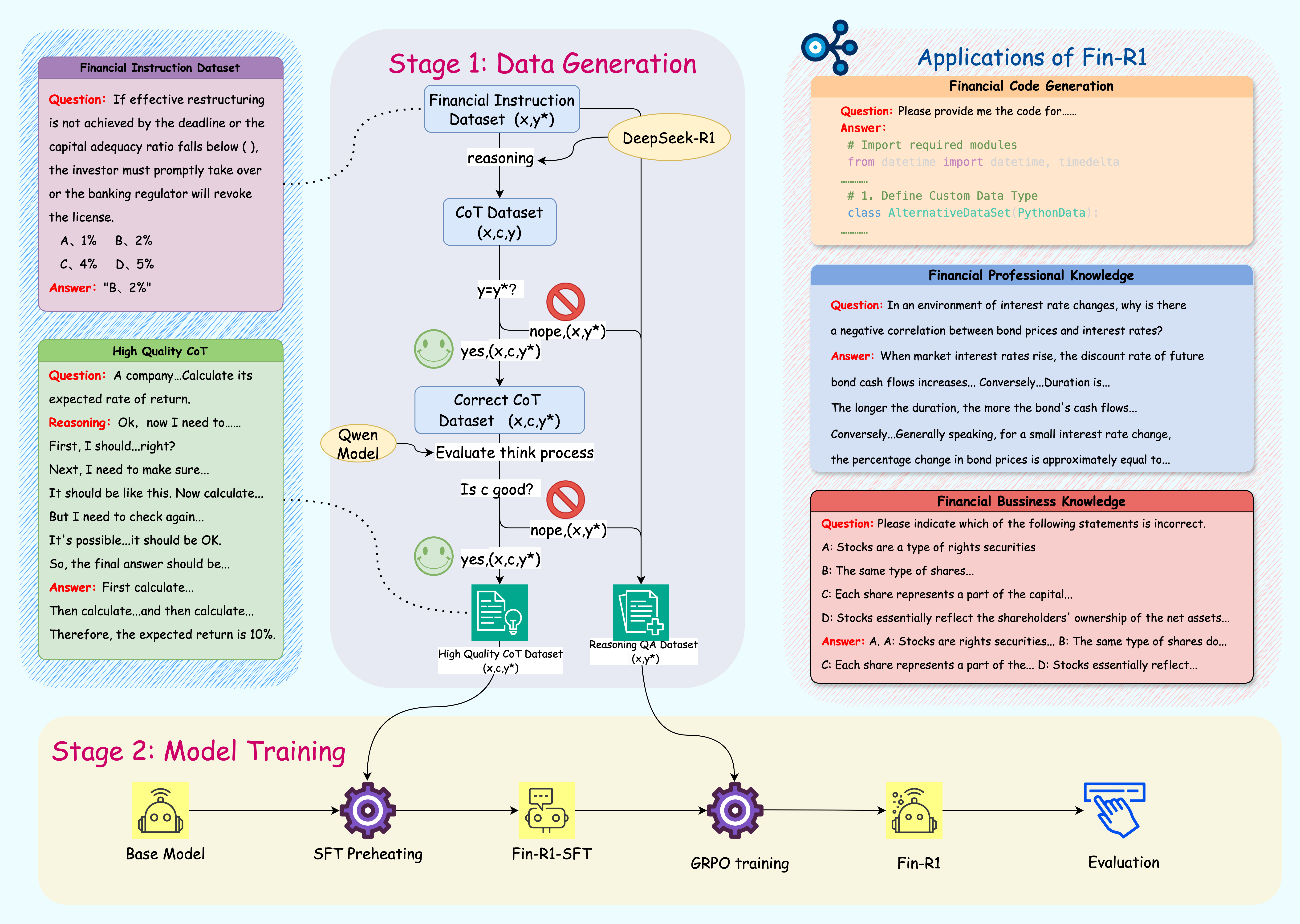 Fin-R1仅7B参数,但在权威评测中,与参数量为671B的行业标杆DeepSeek-R1平均分差距仅3分,以75.2分的平均得分位居评测榜单第二。Fin-R1通过构建高质量金融推理数据集与两阶段混合框架训练,验证了金融领域R1 类推理大模型的可复现性,并探索出了金融领域“数据构建-模型训练-性能验证-模型部署-场景应用”的全闭环链路,将推动大模型在金融领域加快落地。
Fin-R1仅7B参数,但在权威评测中,与参数量为671B的行业标杆DeepSeek-R1平均分差距仅3分,以75.2分的平均得分位居评测榜单第二。Fin-R1通过构建高质量金融推理数据集与两阶段混合框架训练,验证了金融领域R1 类推理大模型的可复现性,并探索出了金融领域“数据构建-模型训练-性能验证-模型部署-场景应用”的全闭环链路,将推动大模型在金融领域加快落地。
基于Baichuan
DISC-FinLLM
2023-10-25 https://arxiv.org/abs/2310.15205 https://github.com/FudanDISC/DISC-FinLLM
DISC-FinLLM 是一个专门针对金融场景下为用户提供专业、智能、全面的金融咨询服务的金融领域大模型,由复旦大学数据智能与社会计算实验室 (Fudan-DISC) 开发并开源。基于Baichuan-13B-Chat
Baichuan4-Finance
2025-01-02 https://arxiv.org/abs/2412.15270 基于Baichuan4-Turbo base
其他
CFGPT
2023-09-22
https://arxiv.org/abs/2309.10654
https://github.com/TongjiFinLab/CFGPT
基于InternLM(书生·浦语2),https://internlm.intern-ai.org.cn/
同时还融合了检索增强模块,事实检测模块,合规检查模块和风险监测模块,在提升金融大模型服务的实时性与准确性的同时,有效监测与管控金融风险。
FinTral
2024-06-14 https://arxiv.org/abs/2402.10986 我们推出了 FinTral,这是一套基于 Mistral-7b 模型构建的、专为金融分析量身定制的最先进的多模态大型语言模型 (LLMs)。FinTral 集成了文本、数字、表格和图像数据。我们利用为这项工作精心挑选的大量文本和视觉数据集,通过特定领域的预训练、指令微调和 RLAIF 训练增强了 FinTral。
Deepmoney
2024-01-22 https://huggingface.co/TriadParty DeepMoney是一个专注于金融领域投资的大型语言模型项目。该模型基于Yi-34B、DeepSeek 67B、miqu-70b构建,当前作者微调了三个模型版本:base和sft (基于yi-34B)、deepmoney-67b-chat (DeepSeek) ,和deepmoney-miqu-70b(migu-70b)。 基座采用了长上下文的yi-34b-200k 零一万物 CEO李开复 https://www.lingyiwanwu.com/
正如我刚才所说,很多公开知识的有效性都有些问题——但这并不意味着它们是错误的。在研报中很多研究方法背后的理论支撑也依赖这些知识。所以在我的训练中,我挑选了一些大学教材和一些专业书籍。数量不是很多但质量还不错。另外,我挑选了在2019-2023年12月的大量研究报告数据——这些报告的发布者多种多样,有传统的broke,也有专业研究机构。他们中的大多数是付费的,而且只对机构提供。但无论如何我通过各种各样的手段获取了它们。 如果你看过研报,尤其是高质量的那些,你会发现研报都是主观判断+定量分析,而定量分析中的数据支撑对于整个逻辑链条至关重要。为了提取这些数据(他们中的大多数以图形或者表格的形式出现),我尝试了很多多模态模型,过程非常痛苦,结论是cog-agent和emu2对于这类任务很有效。为了更好的提取信息,我制作了一套从研报上下文总结作为prompt一部分的流程。 最后,我把这些数据做了一个混合。并没有放入通识数据, 因为它就是为了greed而生的。而且行业研报中的知识足够全。
FinVis-GPT
2023-07-21 https://arxiv.org/abs/2308.01430 用于金融图表分析的多模态大型语言模型 FinVis-GPT 模型建立在现有的 LLaVA Liu 等人( 2023 ) 模型之上,吸收了后者的高级语言能力,并针对特定的金融环境进行了扩展,模型架构如图 2 所示。训练过程包括两个主要步骤:训练前对齐和指令调整。
