作为设计师,在研究AI过程中读过的一些文章,有一些理论的,也有一些应用的思考,能够帮助建立对AI的基本认知。
这篇文章并不是一份“最新AI动态”的汇总,它是在2024年左右研究AI的过程中整理的,没有刻意排版和总结,更像是个阅读时的演草纸。
关于ChatGPT的五个最重要问题
https://docs.qq.com/doc/DQ0plY0JDbXFKUmtU #综述
浅谈人工智能:现状、任务、构架与统一 | 正本清源
https://mp.weixin.qq.com/s/-wSYLu-XvOrsST8_KEUa-Q https://zhusongchun.net/ 2017-11-02 #人工智能 #朱松纯 #综述
有了物理环境的因果链和智能物种的任务与价值链,那么一切都是可以推导出来的。要构造一个智能系统,如机器人或者游戏环境中的虚拟的人物,我们先给他们定义好身体的基本行动的功能,再定一个模型的空间(包括价值函数)。
通讯学习Communicative Learning
这个学习过程是建立在认知构架之上的(第六节讲过的构架)。我把这种广义的学习称作通讯学习Communicative Learning,见下图。
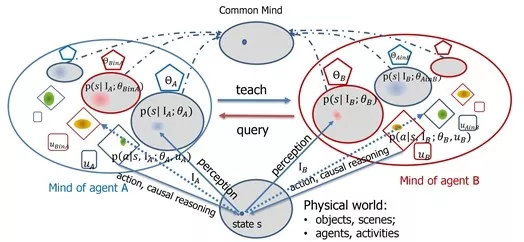
这个图里面是两个人A与B的交流,一个是老师,一个是学生,完全是对等的结构,体现了教与学是一个平等的互动过程。每个椭圆代表一个脑袋mind,它包含了三大块:知识theta、决策函数pi、价值函数mu。最底下的那个椭圆代表物理世界,也就是“上帝”脑袋里面知道的东西。上面中间的那个椭圆代表双方达成的共识。
这个通讯学习的构架里面,就包含了大量的学习模式,包括以下七种学习模式(每种学习模式其实对应与图中的某个或者几个箭头),这里面还有很多模式可以开发出来。
- 被动统计学习passive statistical learning:上面刚刚谈到的、当前最流行的学习模式,用大数据拟合模型。
- 主动学习active learning:学生可以问老师主动要数据,这个在机器学习里面也流行过。
- 算法教学algorithmic teaching:老师主动跟踪学生的进展和能力,然后,设计例子来帮你学。这是成本比较高的、理想的优秀教师的教学方式。
- 演示学习learning from demonstration:这是机器人学科里面常用的,就是手把手叫机器人做动作。一个变种是模仿学习immitation learning。
- 感知因果学习perceptual causality:这是我发明的一种,就是通过观察别人行为的因果,而不需要去做实验验证,学习出来的因果模型,这在人类认知中十分普遍。
- 因果学习causal learning:通过动手实验, 控制其它变量, 而得到更可靠的因果模型, 科学实验往往属于这一类。
- 增强学习reinforcement learning:就是去学习决策函数与价值函数的一种方法。
当言语无法描述时:超越对话界面的人工智能设计
https://mp.weixin.qq.com/s/VOP_JrJ3flst592ZCaajEQ https://www.smashingmagazine.com/2024/02/designing-ai-beyond-conversational-interfaces/ 2024-02-02 #语音交互
人工智障 2 : 你看到的AI与智能无关
https://mp.weixin.qq.com/s/KF4DgF9FPYW2D_M-uacNaw 2019-01-17 (于2021-08-10修改) #对话智能
“ 对话的最终目的是为了同步思维 ”
在信息丰富的程度上,语言是贫瘠的,而思想则要丰富很多 “Language is sketchy, thought is rich” (New perspectives on language and thought,Lila Gleitman, The Oxford Handbook of Thinking and Reasoning;更多相关讨论请看, Fisher & Gleitman, 2002; Papafragou, 2007)
==技术不够的时候,设计来补==。做AI产品的同学,不要期待给你智能。要是真的有智能了,还需要你干什么?人工智能产品经理需要设计一套庞大的系统,其中包括了填表、也当然包括深度学习带来的意图识别和实体提取等等标准做法、也包括了各种可能的对话管理、上下文的处理、逻辑指代等等。 这些部分,都是产品设计和工程力量发挥的空间。
AI 的to C 终极产品是智能助理
我们需要的是对话系统后面的思考能力,解决问题的能力。而对话,只是这个思考能力的交互方式(Conversational User Interface)。如果真能足够聪明的把问题提前解决了,用户甚至连话都不想说。
从这个角度出发,==**对话智能类的产品最核心的价值,是进一步的代替用户的重复思考。==**Work on the mind not the mouth. 哪怕已经是在解决脑袋的问题,也尽量去代替用户系统2的工作,而不只是系统1的工作。
在你的产品中,加入专业级的推理;帮助用户进行抽象概念与具象细节之间的转化;帮助用户去判断那些出现在他的模型中,但是他口头还没有提及的问题;考虑他当前的环境模型、发起对话时所处的物理时空、过去的经历;推测他的心态,他的世界模型。
先解决思考的问题,再尽可能的转化成语言。
智能客服终将被颠覆,进化为下一代智能服务
https://mp.weixin.qq.com/s/mT-L1E9wqsxgIT38pBPnUw 2021-04-29 #对话智能
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
https://zhuanlan.zhihu.com/p/49271699 2018-11-25 #预训练模型 #LLM原理
通向AGI之路:大型语言模型(LLM)技术精要
https://zhuanlan.zhihu.com/p/597586623 2023-01-18 #LLM原理 #综述
范式转换1.0: 从深度学习到两阶段预训练模型 范式转换2.0: 从预训练模型走向通用人工智能 (AGI,Artificial General Intelligence)
具体而言,zero shot prompting的初衷,其实就是人类和LLM的理想接口,直接用人类所习惯的任务表述方式让LLM做事情,但是发现LLM并不能很好地理解,效果也不好。经过继续研究,转而发现:对于某项任务,如果给LLM几个示例,用这些示例来代表任务描述,效果会比zero shot prompting好,于是大家都去研究更好的few shot prompting技术。可以理解为,本来我们希望LLM能够用人类常用的命令方式来执行某个任务,但是目前技术还做不到,所以退而求其次,用这些替代技术来表达人类的任务需求。 few shot prompting(也被称为In Context Learning)只是一种过渡时期的技术。如果我们能够更自然地去描述一个任务,而且LLM可以理解,那么,我们肯定会毫不犹豫地抛弃这些过渡期的技术,原因很明显,用这些方法来描述任务需求,并不符合人类的使用习惯。
一般我们经常提到的人和LLM的接口技术包括:zero shot prompting、few shot prompting、In Context Learning,以及Instruct。这些其实都是表达某个具体任务的描述方式。不过如果你看文献,会发现叫法比较乱。 其中Instruct 是ChatGPT的接口方式,就是说人以自然语言给出任务的描述,比如“把这个句子从中文翻译成英文”,类似这种。zero shot prompting我理解其实就是现在的Instruct的早期叫法,以前大家习惯叫zero shot,现在很多改成叫Instruct。尽管是一个内涵,但是具体做法是两种做法。早期大家做zero shot prompting,实际上就是不知道怎么表达一个任务才好,于是就换不同的单词或者句子,反复在尝试好的任务表达方式,这种做法目前已经被证明是在拟合训练数据的分布,其实没啥意思。目前Instruct的做法则是给定命令表述语句,试图让LLM理解它。所以尽管表面都是任务的表述,但是思路是不同的。 而In Context Learning和few shot prompting意思类似,就是给LLM几个示例作为范本,然后让LLM解决新问题。我个人认为In Context Learning也可以理解为某项任务的描述,只是Instruct是一种抽象的描述方式,In Context Learning是一种例子示范的例子说明法。当然,鉴于目前这几个叫法用的有点乱,所以上述理解仅代表个人看法。
对于自然语言理解类任务,其技术体系统一到了以Bert为代表的“双向语言模型预训练+应用Fine-tuning”模式; 而对于自然语言生成类任务,其技术体系则统一到了以GPT 2.0为代表的“自回归语言模型(即从左到右单向语言模型)+Zero /Few Shot Prompt(零/少数示例提示语)”模式
各种实验充分证明LLM可以学习各种层次类型的语言学知识,这也是为何使用预训练模型后,各种语言理解类自然语言任务获得大幅效果提升的最重要原因之一
世界知识指的是在这个世界上发生的一些真实事件(事实型知识,Factual Knowledge),以及一些常识性知识(Common Sense Knowledge)。
LLM研究趋势及值得研究的重点方向(2023-01)
- 探索LLM模型的规模天花板
- 增强LLM的复杂推理能力
- LLM纳入NLP之外更多其它研究领域
- 更易用的人和LLM的交互接口
- 建设高难度的综合任务评测数据集
- 高质量数据工程
- 超大LLM模型Transformer的稀疏化
ChatGPT的各项超能力从哪儿来?万字拆解追溯技术路线图来了!
https://mp.weixin.qq.com/s/7N3HveaIfn2N-zKjBoRL1A 2022-12-21 #LLM原理 #chatGPT原理
关于AGI与ChatGPT,Stuart Russell与朱松纯这么看
https://mp.weixin.qq.com/s/TL1TCfQMetQh2nM3XykRBg 2023-02-27 #朱松纯
- 通用智能体能够处理无限任务,包括那些在复杂动态的物理和社会环境中没有预先定义的任务;
- 通用智能体应该是自主的,也就是说,它应该能够像人类一样自己产生并完成任务;
- 通用智能体应该具有一个价值系统,因为它的目标是由价值定义的。智能系统是由具有价值系统的认知架构所驱动的
- 大型语言模型在处理任务方面的能力有限,它们只能处理文本领域的任务,无法与物理和社会环境进行互动。这意味着像 ChatGPT 这样的模型不能真正 “理解” 语言的含义,因为它们没有身体来体验物理空间。只有将人工智能体放置于真实的物理世界和人类社会中,它们才能切实了解并习得真实世界中事物之间的物理关系和不同智能体之间的社会关系,从而做到 “知行合一”。
- 大型语言模型也不是自主的,它们需要人类来具体定义好每一个任务,就像一只 “巨鹦鹉”,只能模仿被训练过的话语。真正自主的智能应该类似于 “乌鸦智能”,乌鸦能够自主完成比现如今的 AI 更加智能的任务,当下的 AI 系统还不具备这种潜能。
- 虽然 ChatGPT 已经在不同的文本数据语料库上进行了大规模训练,包括隐含人类价值观的文本,但它并不具备理解人类价值或与人类价值保持一致的能力,即缺乏所谓的道德指南针。
如何利用GPT开发智能应用?微软提出这九大原则
https://mp.weixin.qq.com/s/z91buui-jCaRZNO2jOsY3Q #chatGPT应用
ChatGPT不会取代谷歌搜索,但会颠覆云计算平台
https://mp.weixin.qq.com/s/7HLtL5fkIkFNe2ZGxMwJ2g 2022-12-12 #chatGPT应用
ChatGPT不是或不只是取代谷歌搜索,OpenAI 会颠覆亚马逊云在内的计算平台 商业市场在企业服务(ToB),不在消费者(ToC)
WAIC 2023 | 张俊林:大语言模型带来的交互方式变革
https://www.jiqizhixin.com/articles/2023-07-15-2 2023-07-15
从软件范式到模型范式,什么是 AI-Native 时代的大产品
https://mp.weixin.qq.com/s/avnK5hT6ro7jOw5WXENy6g 2024-02-17 #AGI应用
GenAI 对信息商品经济不同环节的影响:
生产环节:GenAI 技术对信息商品经济最为本质和深刻的影响将发生在生产环节,这种影响也会传导至分配和消费环节,具体来说:
信息商品的生产效率不再受到生产者的时间和精力束缚,创意和算力将成为信息商品的关键生产要素,信息商品的实时生产、定制化生产成为可能
信息商品的单个生产者能力将史诗级增强,在 GenAI 算法的帮助下,单个生产者可以做到更多的事情,比如文本创作者也可以拥有图像创作的能力
信息商品的生产范围将更加社会化,信息商品生产者和消费者的界限将变得更加模糊,生产者可以从自己的消费需求出发来生产内容,消费者也可以在消费信息的过程中生产出新的信息商品
分配环节:由于 GenAI 对生产环节的影响,信息商品分配环节的价值会减少甚至消失,原因在于生产端将从库存逻辑向订单逻辑变化,从「需要什么,分配什么」向「需要什么,生产什么」进行转变,这一部分在前文《LLM-Native 产品的变与不变》中已经有过相关介绍,这里不做赘述
消费环节:消费环节的变化主要来源于信息商品的生产方式以及生产能力的变化,具体来说:
用户消费的信息商品的类型会由 GenAI 算法的能力决定,媒介即信息,消费者能够消费什么信息商品一定程度上取决于生产端能够生产出什么类型的商品,比如手机设备的媒介特点会决定短视频的内容类型
用户消费信息商品的方式将从 GUI 向 GUI+LUI 进行转变,交互从追求效率到兼具灵活,这是 GenAI 主要由语言输入来发起生产决定的,一种正在发生的趋势是:使用 LUI 的灵活性覆盖 GUI 无法覆盖的场景,而高价值 LUI 则会被沉淀为 GUI,比如,将常用的 prompt 设计为独立 bot 或者一个按钮就是这个过程的产物
产生新的信息商品类型,即 GenAI 带来全新的信息商品类型,虽然我们还无法想象具体的新产品会是什么样,但是通过前文的分析,我们也许可以从以下维度来思考可能会有哪些新的信息商品类型出现:
可交互的信息:即一份信息在消费时可以与用户进行交互并根据交互内容产生新的信息,在没有 GenAI 的时代只能通过人工设计交互路径(比如GalGame),而拥有 GenAI 后可交互信息可能会迎来全新可能
信息的模态融合:即不同信息模态在同一个信息商品中是可以同时存在并相互转化的,这来源于不同模态的信息在 GenAI 的技术下是可以不依赖人类进行生产
AI-Native 产品的目标是不断增强解决某种问题的模型智慧水平
LLM-Native产品的变与不变
https://mp.weixin.qq.com/s/0fTsG4aRvVauYbuAzt5BmQ 2023-08-08 #AGI应用
需求的无损传递与个性化满足
对于产品有这样一种表述:对用户需求抽象后的解决方案实现。那么从这个角度来看,产品功能其实是对用户需求的接收和翻译。
在实际产品工作中,无论是对需求的人为抽象还是对功能的人工设计,都无法实现用户需求的无损传递,而功能的标准化设计则注定其无法满足用户的个性化需求,那么不可避免的结果会是:
- 总有人不满意——功能设计的标准化与用户需求的个性化矛盾。
- 功能变复杂——为了更精确翻译更多的用户需求,不得不增加功能。
- 学习门槛增加——功能变多,以及单个功能与用户需求的匹配度降低。
通过对互联网信息内容的压缩来延伸人类的部分智慧能力。
一个愈发明显的趋势是用户需求和指令的分离,即会有一个专门的指令生成环节来连接用户需求和LLMs(Agent便是这种趋势下的必然产物)。
上一个交互范式的工作目标为「如何更好的告诉机器该如何遵循用户指令」(Command-Based Interaction Design),而新的AI交互范式下,工作目标将更新为「如何更好让机器知道用户想要什么」(Intent-Based Outcome Specification)
🌟🌟🌟🌟🌟 《综述:全新大语言模型驱动的Agent》——4.5万字详细解读复旦NLP和米哈游最新Agent Survey
https://zhuanlan.zhihu.com/p/656676717 2023-09-18 #Agent #综述
复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来
https://zhuanlan.zhihu.com/p/656875986 2023-09-18 #Agent
智能代理的框架也由三个部分组成:控制端(Brain)、感知端(Perception)和行动端(Action)。
- 控制端:通常由 LLMs 构成,是智能代理的核心。它不仅可以存储记忆和知识,还承担着信息处理、决策等不可或缺的功能。它可以呈现推理和计划的过程,并很好地应对未知任务,反映出智能代理的泛化性和迁移性。
- 感知端:将智能代理的感知空间从纯文本拓展到包括文本、视觉和听觉等多模态领域,使代理能够更有效地从周围环境中获取与利用信息。
- 行动端:除了常规的文本输出,还赋予代理具身能力、使用工具的能力,使其能够更好地适应环境变化,通过反馈与环境交互,甚至能够塑造环境。
🌟🌟🌟🌟🌟 从 CoT 到 Agent,最全综述来了!上交出品
![[从 CoT 到 Agent.canvas]] https://zhuanlan.zhihu.com/p/668914454 2023-11-26 #Agent #LLM原理
为什么要使用 CoT ?
1. **增强了大模型的推理能力**:CoT 通过将复杂问题分解为多步骤的子问题,相当显著的增强了大模型的推理能力,也最大限度的降低了大模型忽视求解问题的“关键细节”的现象,使得计算资源总是被分配于求解问题的“核心步骤”;
2. **增强了大模型的可解释性**:对比向大模型输入一个问题大模型为我们仅仅输出一个答案,CoT 使得大模型通过向我们展示“做题过程”,使得我们可以更好的判断大模型在求解当前问题上究竟是如何工作的,同时“做题步骤”的输出,也为我们定位其中错误步骤提供了依据;
3. **增强了大模型的可控性**:通过让大模型一步一步输出步骤,我们通过这些步骤的呈现可以对大模型问题求解的过程施加更大的影响,避免大模型成为无法控制的“完全黑盒”;
4. **增强了大模型的灵活性**:仅仅添加一句“Let's think step by step”,就可以在现有的各种不同的大模型中使用 CoT 方法,同时,CoT 赋予的大模型一步一步思考的能力不仅仅局限于“语言智能”,在科学应用,以及 AI Agent 的构建之中都有用武之地。
首先,CoT 需要大模型具备一些方面“最基础”的知识,如果模型过小则会导致大模型无法理解最基本的“原子知识”,从而也无从谈起进行推理;其次,使用 CoT 可以为一些它理解到的基础知识之间搭起一座桥梁,使得已知信息形成一条“链条”,从而使得大模型不会中途跑偏;最后,CoT 的作用,或许在于强迫模型进行推理,而非教会模型如何完成推理,大模型在完成预训练后就已经具备了推理能力,而 CoT 只是向模型指定了一种输出格式,规范模型让模型逐步生成答案。
Agent is all you need | AI智能体前沿进展总结
https://zhuanlan.zhihu.com/p/655425020 2023-09-10 #Agent #综述
2024年大模型Multi-agent多智能体应用技术:AutoGen, MetaGPT, XAgent, AutoAgents,crewAI
https://zhuanlan.zhihu.com/p/671355141 2024-01-16 #Agent
MetaGPT侧重的是角色扮演,AutoGen侧重的是conversation和 python programming,AutoAgents侧重的是协作,XAgent强调的是外循环和内循环完成复杂任务的形式。后面各大厂家纷纷发布了自己的Agent项目。比如AppAgent,KwaiAgents,Pangu-Agent,modelscope-agent,ERNIE Bot Agent都各具特色,还有一些机构发布的Agents,例如清华的AgentVerse,港大的OpenAgents等等, 从侧面说明,Agent这个东西没什么特别高的技术门槛,如果效果不好,直接标数据SFT就行,产生价值的地方就是在应用上面,比如一些传统业务的降本增效,创新业务落地成爆款应用等等。
2023年新生代大模型Agents技术,ReAct,Self-Ask,Plan-and-execute,以及AutoGPT, HuggingGPT等应用
https://zhuanlan.zhihu.com/p/642357544 2024-01-14 #Agent
